What is Deep Learning?
Deep learning is a subset of machine learning and artificial intelligence (AI) that models how people acquire specific types of knowledge. Deep learning is a key component of data science, which also includes statistics and predictive modeling. Deep learning streamlines data analysis, making it faster and more efficient. This is particularly beneficial for data scientists, who often work with massive datasets, simplifying their tasks of data collection, analysis, and interpretation.

At its most basic, deep learning can be thought of as a way to automate predictive analytics. Unlike traditional machine learning algorithms, which are linear, deep learning algorithms are stacked in a hierarchy of increasing complexity and abstraction.
Imagine a toddler learning the concept of a “dog”. They started by pointing at objects and saying “dog”. Their parents correct them saying “yes” or “no”. Through this process, the child builds a mental hierarchy of what makes a dog “a dog”. They learn to recognize patterns and characteristics that defines a dog, and they refine their understanding with each new experience. This process illustrates how deep learning works, where complex abstractions are broken down into simpler, hierarchical representations.
How Does Deep Learning Work?
Similar to how a child learns to recognize a dog, deep learning computer algorithms go through phases. After applying a nonlinear modification to its input, each algorithm in the hierarchy uses what it has learned to generate a statistical model as its output. Iterations continue until the outcome is accurate enough to be accepted. This multi-layered processing is called “deep” learning.
Typical machine learning is supervised, meaning programmers must explicitly tell the computer what to look for in an image to identify a dog. The computer’s accuracy depends on the programmer’s anbility to define to define the features of a dog. Deep learning, on the other hand, allows the software to develop its own feature set without supervision. This unsupervised learning approach is not only faster but also more accurate.
Training data, such as a set of photos with metatags applied to each one to identify whether or not it is a dog image, may be initially provided to the computer program. With the knowledge it gains from the training data, the computer creates a predictive model and a feature set for the dog. In this case, anything in the picture that has four legs and a tail might be categorized as a dog according to the computer’s original model. Naturally, the software is unaware of the terms “four legs” and “tail.” All it will do is look for pixel patterns in the digital data. With every iteration, the predictive model’s accuracy and complexity increase.
Software leveraging deep learning algorithms can rapidly analyze millions of images, pinpointing those featuring dogs with remarkable precision – all within minutes. This contrast sharply with human development, where recognizing dogs takes a child weeks or months. To achieve reliable results, deep learning system require vast training datasets and substantial computational power. However, these resources only become widely accessible with the advent of big data and cloud computing.
Deep learning programming excels at crafting accurate predictive models from vast amount of unstructured, unlabeled data. By generating intricate statistical models through iterative processes, deep learning tackles the complexities of the expanding Internet of Things (IoT), where most data from humans and devices remains unstructured and unlabeled.
Deep learning methods
Numerous methods can be used to create powerful deep-learning models. Dropout, learning rate decay, transfer learning, and beginning from scratch are some of these techniques.
Learning rate decay:
Every time the model weights are changed, the learning rate—a hyperparameter—controls how much the model responds to the estimated error. A hyperparameter is an element that defines the system or gives the conditions for its functioning before the learning process begins. Unstable training procedures or the acquisition of a less-than-ideal set of weights could result from excessive learning rates. A lengthy training process with the risk of becoming stuck could result from learning rates that are too slow.
A technique for altering the learning rate to improve performance and shorten training times is the learning rate decay method, also known as learning rate annealing or adaptable learning rates. Slowing down over time is one of the simplest and most popular methods to change the learning rate during training.
Transfer learning:
This method, known as transfer learning or fine-tunning enhancing a pre-trained model by granting access to its internal workings. The process begins by introducing new, classified data-including previously unknown categories- into existing network. Once the network is updated, it can tackle new tasks with improved classification capabilities. The benefit of this approach is that it uses a lot less data than other approaches, cutting down on computation time to a few minutes or hours.
Training from scratch:
For this method to work, a large labeled data set must be obtained and a network architecture that can learn the model and features must be developed. Apps with multiple output categories and new applications may find this strategy to be highly beneficial. But because it requires a large amount of data and takes days or weeks to train, it is often a less popular approach.
Dropout:
This technique tackles the issue of overfitting in neural networks with numerous parameters by randomly removing units and their connections during training. The dropout technique has been demonstrated to enhance neural network performance on supervised learning tasks in domains like computational biology, document classification, and speech recognition.
Deep Learning V/S Machine Learning
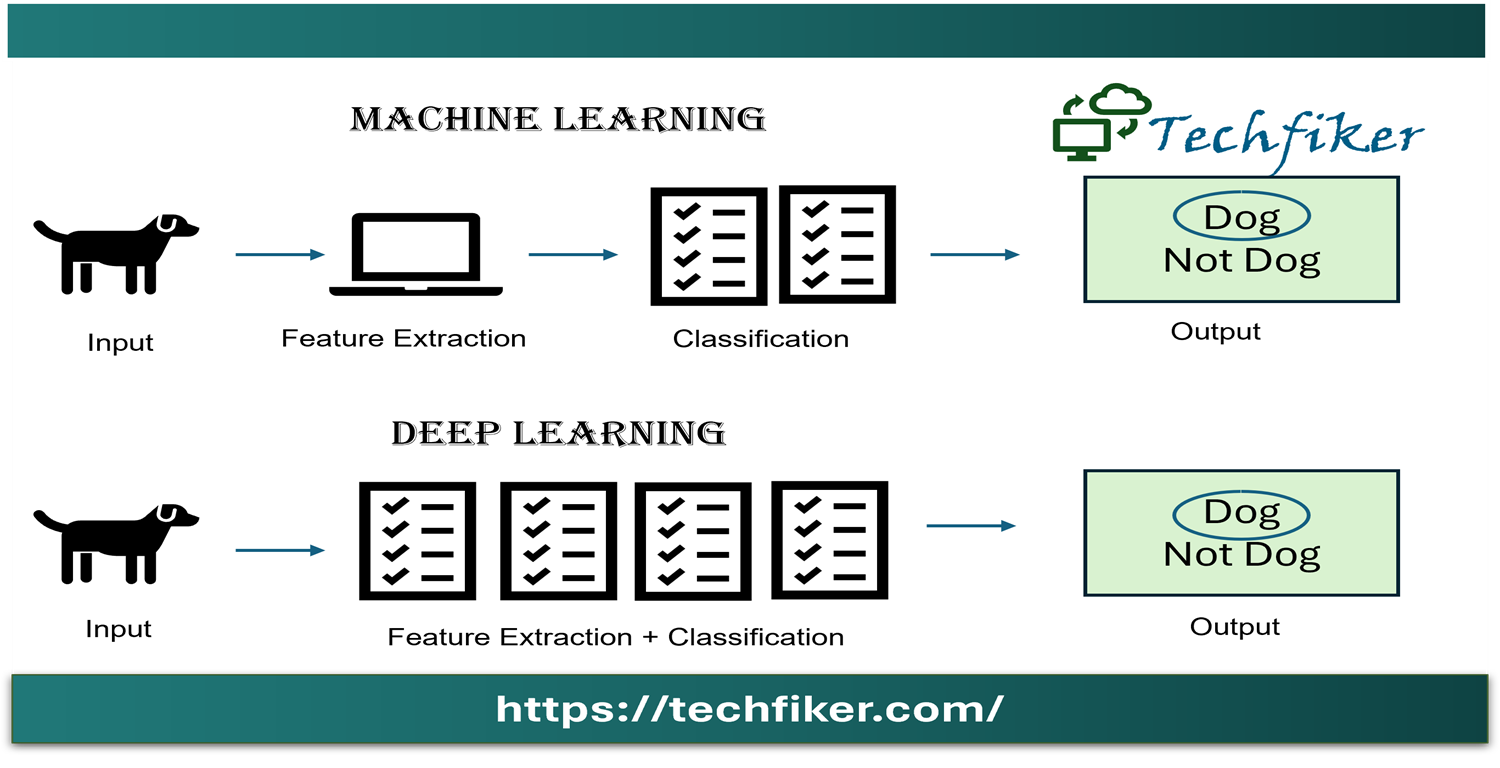
Deep learning a subset of machine learning, stands out due to its unique problem- solving approach. Unlike machine learning, which relies on domain experts to identify key features, deep learning automatically discovers features through iterative learning. This difference impacts training time: deep learning algorithms require longer training periods, while machine learning algorithms can be trained in minutes to hours. However deep learning excels during testing, conducting tests faster than machine learning algorithms, especially with large datasets.
Furthermore, machine learning does not require the same costly, top-tier hardware or potent GPUs as deep learning. Because of its better interpretability—the capacity to understand the outcomes—many data scientists ultimately favor standard machine learning over deep learning. In situations where data is scarce, machine learning techniques are also employed.
You may read our other blogs: